
本記事ではPython環境で使用できるdocx2pdfというライブラリを紹介します。
docx2pdfを使うとPDF化がインストールからたった3行で完了します。
また、grobを使って大量のファイルを連続的にPDF化することも当然できます。
2つの例を使って紹介するので用途にあった使い方をしてください。
①ファイルを指定した単純なPDF化
②大量ファイルを連続的にPDF化
日常業務の中でwordファイルをpdfへ変換しなければならない状況を一度は経験しているかとは思います。
客先への提出書類準備やpdf指定のファイル保管作業などで何種類かのwordファイルを変換しなければならない際は時間がかかってしまいます。
また、周りに大量ファイルの変換を依頼されて困っている方がいたら大変喜ばれるかと思います。
exe化することでPython環境のない方でも使えるのでこちらの記事を参考にしてください。

①ファイルを指定した単純なPDF化
たった3行で完了です。
インストール方法
pip install docx2pdfインポート
convertというライブラリをインポートします。
from docx2pdf import convert convert(‘ファイルパス’)でPDF化が始まります。
convert('test.docx')以上で一番簡単なやり方の説明は終了です。
次に公式サイトの例文からオプションについて解説します。
#ファイル名も変わらずPDF化
convert("input.docx")#ファイル名を指定してPDF化 convert("input.docx", "output.pdf")#フォルダを指定してフォルダ内の全てのファイルをPDF化 convert("my_docx_folder/")
②大量ファイルを連続的にPDF化
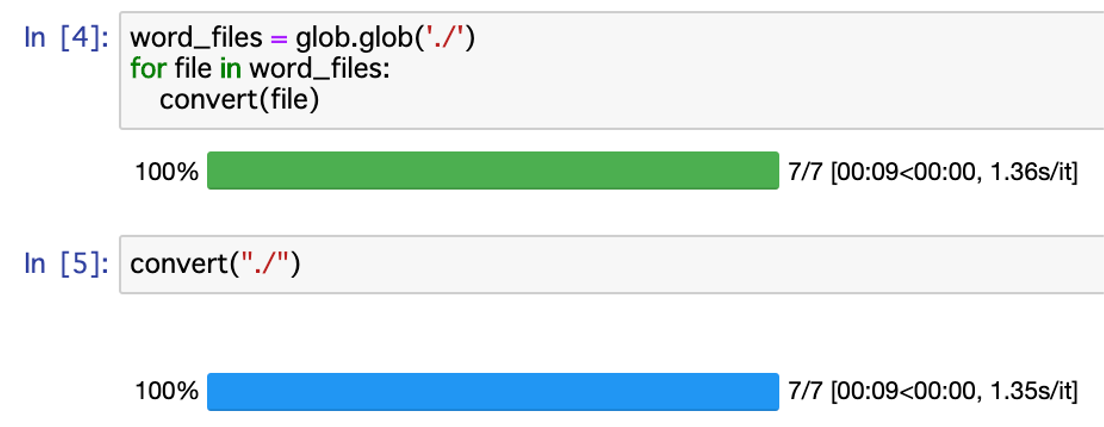
このようにやり方はいくつかありますが、ある名前を含んだワードファイルのみPDF化したい場合など、フォルダ全てファイルは必要ない時にはglobを使用するやり方がおすすめです。
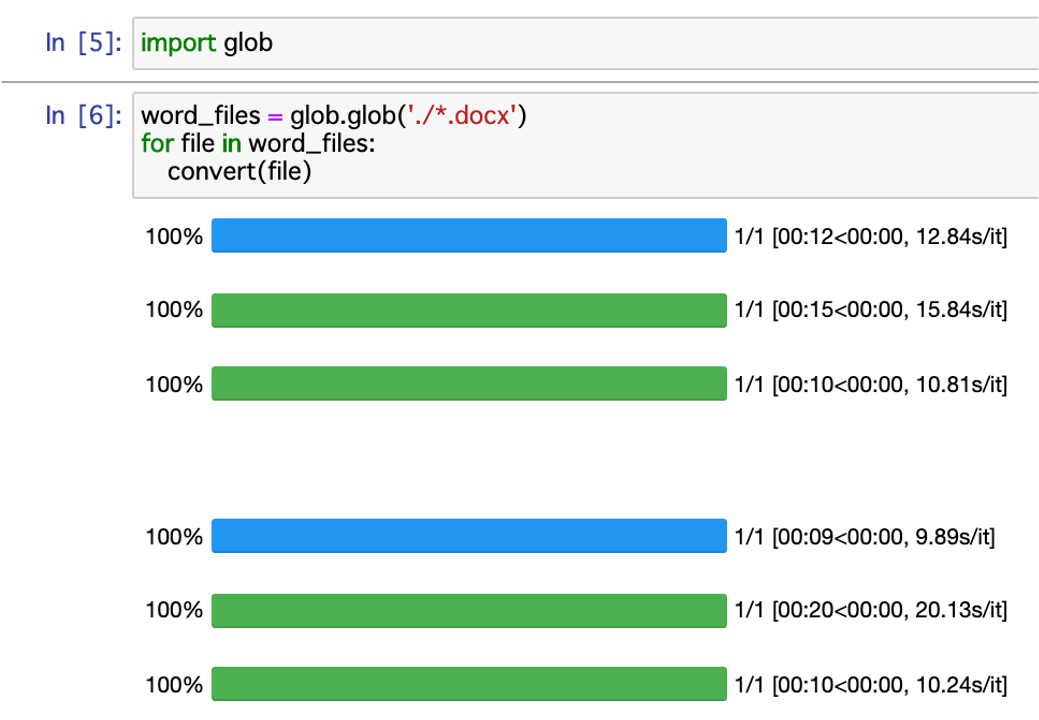
*のところはワイルドカードを使って好きにアレンジしてみて下さい。
例えばファイル名が3文字だけのものを指定したい場合、???.docxとすればOKです。
コードは以下の通りです。
globをインポートします。
import globglob.globでファイルパスを取得し、for文で連続的にconvertしていく流れです。
いろいろなところで使えるテクニックなのでぜひこのやり方もマスターしましょう。
word_files = glob.glob('./*.docx')
for file in word_files:
convert(file)対象のワードファイル全てのPDFが連続的に作成されていきます。
解説は以上です。
このようなPythonファイルをGUIアプリにすると自分だけでなく誰でも使える便利なアプリになります。
















