環境準備
jupyter notebook導入
はず始めに、初心者向けにjupyter notebookの導入方法を説明します。
既に環境のある方はスキップして下さい。
まずはAnacondaをインストールする必要があります。
まだインストールしていない方は下記記事を参考にしてください。

Anacondaのインストールが完了したら次はJupyter notebookの起動です。
Anacondaのインストールが完了したらAnaconda Navigatorを起動します。
その中のJupyter notebookをクリックします。
立ち上がったあとに右側にある「new」→「Python3」を選択すると、以下の画面になります。
ここの入力部分にコマンドを入れて実行するとプログラムが走る仕組みになっています。
データの読み込み
import pandas as pd
import numpy as np
train = pd.read_csv("C:/Users/user/Desktop/titanic/train.csv")
test = pd.read_csv("C:/Users/user/Desktop/titanic/test.csv")train.head()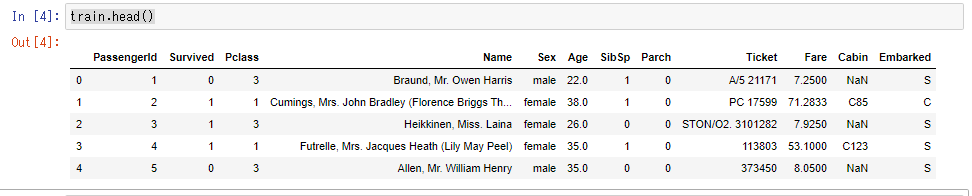
trainデータの全体感が分かります。
データの中身
train.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): PassengerId 891 non-null int64 Survived 891 non-null int64 Pclass 891 non-null int64 Name 891 non-null object Sex 891 non-null object Age 714 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Ticket 891 non-null object Fare 891 non-null float64 Cabin 204 non-null object Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.6+ KB
データ数や列数、欠損データの有無やデータの拡張子が分かります。
Age、Cabin、Embarkedに欠損データがあるのでデータの穴埋めが必要です。
欠損データの総数を知る
train.isnull().sum()PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64
欠損データの穴埋め方法紹介
欠損値を削除する方法
train.dropna() # 欠損値を含む行や列を削除
train.dropna(axis = 'columns') # 欠損値を含む列を削除する
train.dropna(how = 'all') # すべての要素が欠損している行を削除する
train.dropna(thresh = 2) # 欠損していない要素数が2以上の行のみを保持する
train.dropna(subset = ['Age', 'Cabin']) # 列Age, Cabinで欠損値を含む行を削除する
train.dropna().shape #行列の減少を確認する用※注意
drop()を呼び出すだけでは元のデータは変更されないため以下を実行data.dropna(inplace=True)
あるいはdata = data.dropna()
欠損値を穴埋めする方法
train.fillna('FILL')
train['Age'].fillna(20) # 列Ageの欠損値を20で穴埋め
train['Age'].fillna(train['Age'].mean()) # 列Ageの欠損値をAgeの平均値で穴埋め
train['Age'].fillna(train['Age'].median()) # 列Ageの欠損値をAgeの中央値で穴埋め
train['Age'].fillna(train['Age'].mode()) # 列Ageの欠損値をAgeの最頻値で穴埋め
train.fillna(method = 'ffill') # 欠損値に対して前方向に同じ値で穴埋め
train.fillna(method = 'bfill') # 欠損値に対して後方向に同じ値で穴埋めその他使える変換例
train.Embarked = train.Embarked.replace(['C', 'S', 'Q'], [0, 1, 2])
train.Sex = train.Sex.replace(['male', 'female'], [0, 1])
train.Age = train.Age.replace('NaN', 0)
カラムの削除
train.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)タイタニック課題の各パラメータについて
PassengerId: 乗客のID
Survived: 生存(1)、死亡(0)
Pclass: 乗客の階級
Name: 乗客の名前
Sex: 性別
Age: 年齢
SibSp: 兄弟、姉妹、義兄弟、義姉妹、夫、妻の数
Parch: 母親、父親、息子、娘の数
Ticket: チケットナンバー
Fare: 乗船料金
Cabin: キャビン番号
Embarked: 乗船場
Seabornグラフ集
seabornのインストール方法
pip install seaborn全体感を把握する ①ヒストグラムと散布図
import seaborn as sns
import sklearn.preprocessing as sp
df = train
le = sp.LabelEncoder()
le.fit(df.Sex.unique())
df.Sex = le.fit_transform(df.Sex)
sns.pairplot(df,hue='Survived')Survivedで色分けしています。
1・・・生存
0・・・死亡

グラフからPclass(乗客の階級)、Sex(性別)あたりが生存に影響していそうなことが分かります。
全体感を把握する ②相関係数のヒートマップ
sns.heatmap(train.corr(),annot=True)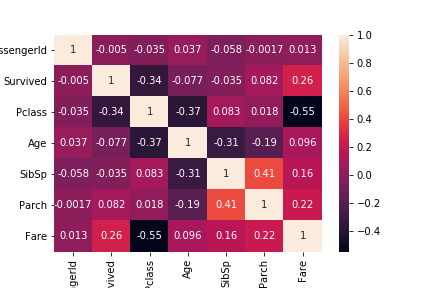
年齢と生存の関係
grid = sns.FacetGrid(df, col='Survived')
grid.map(sns.distplot, 'Age')
grid.add_legend()
plt.savefig("seaborntest1.png")
性別と生存の関係
grid = sns.FacetGrid(df, col='Sex')
grid.map(sns.countplot, 'Survived')
grid.add_legend()
plt.savefig("seaborntest2.png")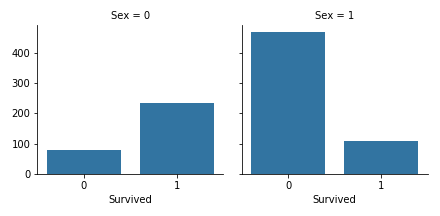
乗客の階級と生存の関係
grid = sns.FacetGrid(df, col='Pclass')
grid.map(sns.countplot, 'Survived')
grid.add_legend()
plt.savefig("seaborntest3.png")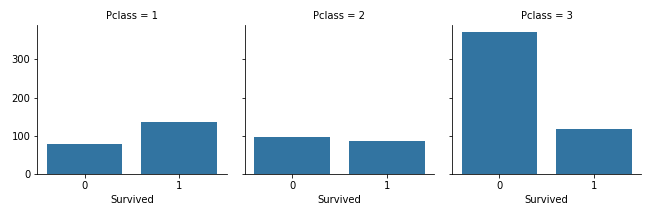
生存と関係ありそうなもの
grid = sns.FacetGrid(df, row='Embarked', size=2.2, aspect=1.6)
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend()
plt.savefig("seaborntest4.png")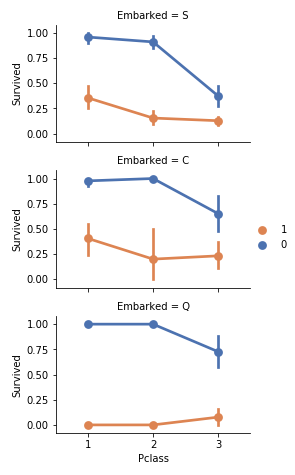
参考サイト
seaborn
pythonで美しいグラフ描画 -seabornを使えばデータ分析と可視化が捗る その1
kaggle
Titanic Data Science Solutions