
データ解析を実務でやっていくために必要なスキルを身につけるためにKaggleやSignateのようなコンテストで課題を解く練習は極めて重要です。
下手に参考書を買って読み込むより、実際に手を動かしてデータ解析の練習をした方が効率よく学べます。
特に初心者のうちは他人のプログラムを写して少しづつ自分でアレンジしていく進め方をおすすめします。
今回紹介するプログラムもコピーしてすぐ使えるものなので参考になれば幸いです。
タイタニックのデータを見たことがない方はまずはこちらの記事でどんなパラメータが存在し、重要なパラメータは何か頭に入れた上で読むと理解が深まります。

LightGBMの特徴
LightGBMはKaggleの上位入賞したモデルの半数を占める定番中の定番の機械学習手法のようです。
以下の特徴があります。
・訓練にかかる時間が短い
→計量値をヒストグラムとして扱うため
・メモリ効率が高い
・過学習しやすい
・大規模データに適している(XGBoostやSVM対比)
LightGBMのインストール
Windows、Mac共通
たった一文でインストール完了です。
conda install -c conda-forge lightgbm
知っておきたい「交差検証)Cross Validation)」
モデル性能の評価について注意したいこととして下記があります。
・一部のデータのみに過学習する(汎化性能があるか)
・提出回数に制限がある
・ホールドアウト検証では検証用に使ったデータセットは訓練に使えない
そこで、上記の対策として交差検証と呼ばれる方法があります。
今回紹介するプログラムでは5つのデータセットに分割してそれぞれで評価し、その5つのモデルでの結果における平均値
ポイントは「生存」「死亡」の割合を一定にすることです。
正解のデータにおける割合を保ったままCross Validationを実施するためにはStratifiedFoldと言う手法を用います。
ただし、この手法を使う際には以下の点に注意が必要です。
・データセット内に時系列性がないか
・データセット内にグループが存在しないか
今回の課題にはこれらは当てはまらないので、StratifiedFoldを使ってデータセットを分割したものを紹介します。
プログラム本体
import numpy as np
import pandas as pd
# LightGBM
import lightgbm as lgb
train = pd.read_table('./train.tsv')
test = pd.read_table('./test.tsv')
train.embarked = train.embarked.replace(['C', 'S', 'Q'], [0, 1, 2])
test.embarked = test.embarked.replace(['C', 'S', 'Q'], [0, 1, 2])
import sklearn.preprocessing as sp
X_train=train.drop('id',axis=1)
X_test=test.drop('id',axis=1)
X_train['family']=X_train['sibsp']+X_train['parch']+1
X_test['family']=X_test['sibsp']+X_test['parch']+1
X_train=X_train.drop('sibsp',axis=1)
X_test=X_test.drop('sibsp',axis=1)
X_train=X_train.drop('parch',axis=1)
X_test=X_test.drop('parch',axis=1)
le = sp.LabelEncoder()
le.fit(X_train.sex.unique())
X_train.sex = le.fit_transform(X_train.sex)
le.fit(X_test.sex.unique())
X_test.sex = le.fit_transform(X_test.sex)
# sns.heatmap(X_train.corr(),annot=True)
X_train=X_train.drop('survived',axis=1)
y_train=train['survived']
categorical_features = ['pclass', 'sex','family','fare']
params = {
'objective': 'binary',
'max_bin': 30,
'learning_rate': 0.001,
'num_leaves': 40
}
# from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
y_preds = []
models = []
oof_train = np.zeros((len(X_train),))
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=1)
for fold_id, (train_index, valid_index) in enumerate(cv.split(X_train, y_train)):
X_tr = X_train.loc[train_index, :]
X_val = X_train.loc[valid_index, :]
y_tr = y_train[train_index]
y_val = y_train[valid_index]
lgb_train = lgb.Dataset(X_tr, y_tr,
categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_val, y_val,
reference=lgb_train,
categorical_feature=categorical_features)
model = lgb.train(params, lgb_train,
valid_sets=[lgb_train,lgb_eval],
verbose_eval=8000,
num_boost_round=5000,
early_stopping_rounds=5000)
oof_train[valid_index] = model.predict(X_val, num_iteration=model.best_iteration)
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_preds.append(y_pred)
models.append(model)
scores = [
m.best_score['valid_1']['binary_logloss'] for m in models
]
score = sum(scores) / len(scores)
print('===CV scores===')
print(scores)
print(score)実行結果
Training until validation scores don't improve for 5000 rounds
Did not meet early stopping. Best iteration is:
[5000] training's binary_logloss: 0.34012 valid_1's binary_logloss: 0.370792
Training until validation scores don't improve for 5000 rounds
Did not meet early stopping. Best iteration is:
[5000] training's binary_logloss: 0.331996 valid_1's binary_logloss: 0.430239
Training until validation scores don't improve for 5000 rounds
Did not meet early stopping. Best iteration is:
[5000] training's binary_logloss: 0.319917 valid_1's binary_logloss: 0.414441
Training until validation scores don't improve for 5000 rounds
Did not meet early stopping. Best iteration is:
[5000] training's binary_logloss: 0.329038 valid_1's binary_logloss: 0.394071
Training until validation scores don't improve for 5000 rounds
Did not meet early stopping. Best iteration is:
[5000] training's binary_logloss: 0.28245 valid_1's binary_logloss: 0.590678
===CV scores===
[0.37079179193015643, 0.4302394765776665, 0.4144412398816655, 0.3940709167584216, 0.5906779783883791]
0.44004428070725776CVスコアは5つの分割した結果についてそれぞれ出力されます。
最終の0.44が5つのデータセットにおける平均値です。
Signateの得点を上げる工夫
今回紹介する工夫は以下の特徴がないことを前提としています。
・データセット内に時系列性がないか
・データセット内にグループが存在しないか
・生存率が訓練用データと提出データで大きく変わらない
(与えられたデータと隠されたデータがランダムである事)
C_train=train
C_train['count']=1
sum(train[train.survived==1]['count'])/sum(train['count'])Out: 0.40224719101123596
このように訓練用データは生存率が0.4程度だという事が分かります。
なので提出用データもだいたいこのくらいになる事を確認してみました。
for i in range(446):
if y_pred[i]>=0.4:
y_pred[i]=1
else:
y_pred[i]=0
import csv
test_data = test.values
with open('./gender_submission.csv', "w") as f:
writer = csv.writer(f, lineterminator='\n')
for pid, survived in zip(test_data[:,0].astype(int), y_pred.astype(int)):
writer.writerow([pid,survived])if y_pred[i]>=0.4:の0.4は普通は0.5を閾値としますが、出力されたgender_submission.csvの中身を見てみると生存率が0.5を超えていました。
なので上記の生存率を0.4に合わせるために調整した結果、0.4としました。(提出するデータの生存率は0.41)
特徴量の重要度を調べる
lgb.plot_importance(model, height=0.5, figsize=(8,8))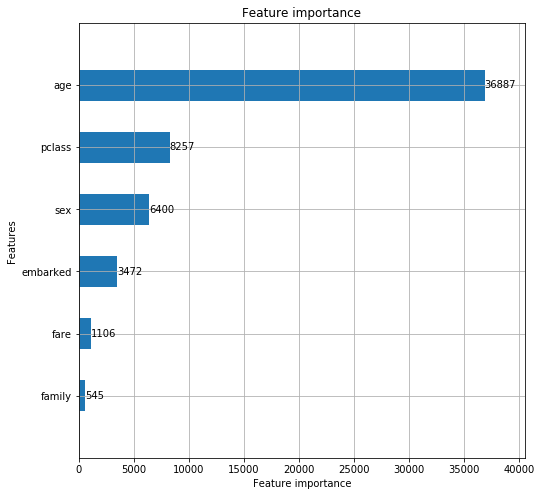
予想に重要だったものをピックアップしてくれます。
性別は重要だと思っていたので意外でした。
後から分かりますが、このアルゴリズムで提出したものの正解率は100%ではないので、この辺りが予想と結果で合わない原因かもしれません。
Signateへ提出
出来上がったgender_submission.csvを下記参考のCSV→TSVへの変換ツールを使って変換して提出します。
正解率は79.4%
結果:206位/806人 (2020年6月13日現在)
でした。
初めてにしてはぼちぼちな結果ですかね。
参考
LightGBM 徹底入門 – LightGBMの使い方や仕組み、XGBoostとの違いについて
Kaggleに登録したら次にやること ~ これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel ~














