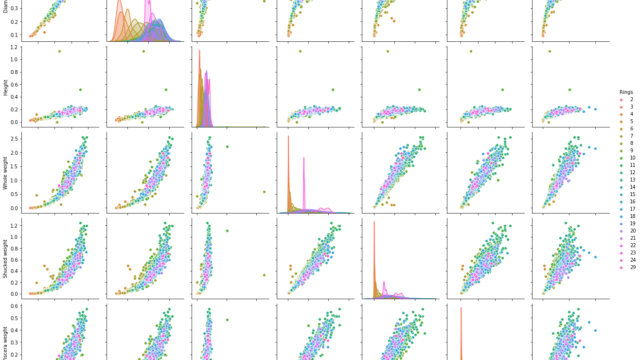
LightGBM(Gradient boosting machine)
LightGBMは教師あり学習手法の一つであるXGBoostの改良版。
XGBoostは「決定木」とアンサンブル学習の一つ「ブースティング」を組み合わせた手法。
※アンサンブル学習は複数のモデルを作って様々な手法で組み合わせる手法。(バギング、ブースティング、スタッキングがある)
XGBoostはブースティングにより決定木を直列に組み合わせたのものであり、PythonやRで簡単に実装できる点がポイントです。
XGBoostのような決定木モデルのメリット
・欠損値補完が不要
・標準化が不要
である点がメリットとして挙げられます。
さてXGBoostとLightGBMの違いを説明します。
結論:計算負荷が低く、効率よく計算できる
その理由として以下の違いがあります。
XGBoost・・・Level-wise tree growth
➡︎階層レベルを合わせて学習していく
LightGBM・・・Leaf-wise tree growth
➡︎葉毎に学習を行っていく (無駄な学習がなくなる)
LightGBMを使った例文
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn import tree
# LightGBM
import lightgbm as lgb
# Scikit-learn(評価算出)
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
train=pd.read_table('./train.tsv')
test=pd.read_table('./test.tsv')
sample=pd.read_csv('./sample_submit.csv')
sub=pd.read_csv('./sub.csv')
X_train=train
X_train=X_train.drop('id',axis=1)
X_train['Sex'] = X_train['Sex'].replace(['M', 'F', 'I'], [float(0.1), float(0.2), float(0.3)])
X_test=test
X_test=X_test.drop('id',axis=1)
X_test['Sex'] = X_test['Sex'].replace(['M', 'F', 'I'], [float(0.1), float(0.2), float(0.3)])
X_train=X_train.drop('Rings',axis=1)
y_train=train['Rings']
# clf = LogisticRegression(penalty='l2', solver='sag', random_state=1)
# clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0)
# clf = tree.DecisionTreeRegressor(max_depth=3, random_state=0)
categorical_features = ['Length', 'Height','Viscera weight','Shell weight','Diameter','Whole weight']
# categorical_features = ['Length','Shell weight']
params = {
'objective': 'regression',
'learning_rate': 0.0001,
'metric': ('mean_absolute_error', 'mean_squared_error', 'rmse'),
'drop_rate': 0.15,
'verbose': 0,
'max_depth': -1, # 木の数 (負の値で無制限)
'num_leaves': 9 # 枝葉の数
}
from sklearn.model_selection import StratifiedKFold
y_preds = []
models = []
oof_train = np.zeros((len(X_train),))
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=1)
for fold_id, (train_index, valid_index) in enumerate(cv.split(X_train, y_train)):
X_tr = X_train.loc[train_index, :]
X_val = X_train.loc[valid_index, :]
y_tr = y_train[train_index]
y_val = y_train[valid_index]
lgb_train = lgb.Dataset(X_tr, y_tr,
categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_val, y_val,
reference=lgb_train,
categorical_feature=categorical_features)
model = lgb.train(params, lgb_train,
valid_sets=[lgb_train,lgb_eval],
verbose_eval=100000,
num_boost_round=100000,
early_stopping_rounds=1000)
oof_train[valid_index] = model.predict(X_val, num_iteration=model.best_iteration)
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_preds.append(y_pred)
models.append(model)
scores = [
m.best_score['valid_1']['rmse'] for m in models
]
score = sum(scores) / len(scores)
print('===CV scores===')
print(scores)
print(score)
# confusion_matrix(y_val, y_pred)
# accuracy_score(y_val, y_pred)
# y_pred = clf.predict(df)
# sub['Rings'] = list(map(int, y_pred))
# sub.to_csv('submission.csv', index=False)===CV scores===
[2.566186809212052, 2.711103101245421, 2.619344503110226, 2.5886178547184433, 2.6760011006839357]
2.6322506737940152
for i in range(2089):
y_pred[i]=(y_pred[i])
import csv
test_data = test.values
with open('./gender_submission.csv', "w") as f:
writer = csv.writer(f, lineterminator='\n')
for pid, survived in zip(test_data[:,0].astype(int), y_pred.astype(int)):
writer.writerow([pid,survived])参考記事
LightGBM 徹底入門 – LightGBMの使い方や仕組み、XGBoostとの違いについて