決定木を使った例
import pandas as pd
import numpy as np
import seaborn as sns
import sklearn.preprocessing as sp
import pydotplus
from IPython.display import Image
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn import tree
# Scikit-learn(評価算出)
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn import metrics
# graphvizのdotファイルを生成する
from sklearn import datasets
from sklearn.cluster import MiniBatchKMeans
from sklearn import tree
train=pd.read_table('./train.tsv')
test=pd.read_table('./test.tsv')
sub=pd.read_csv('./sample_submit.csv')
drop_col = ['id','native-country','education','workclass','sex','race','fnlwgt','occupation','marital-status','capital-loss','capital-gain','hours-per-week']
train=train.drop(drop_col, axis=1)
test=test.drop(drop_col, axis=1)
l = ['relationship']
le = sp.LabelEncoder()
for name in l:
le.fit(train[name].unique())
le.fit(test[name].unique())
train[name] = le.fit_transform(train[name])
test[name] = le.fit_transform(test[name])
train["Y"] =train["Y"].replace(['<=50K', '>50K'], [0, 1])
#############################
# sns.heatmap(X_train.corr(),annot=True)
# sns.pairplot(X_train,hue='Y')
#############################
Y=train['Y']
X=train.drop('Y', axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=1)
clf=tree.DecisionTreeRegressor(max_depth=20, random_state=1)
clf.fit(X_train, y_train)
y_pred = clf.predict(test)
print ('Score: ',clf.score(X_test, y_test))#正解率の表示
#K分割交差検証
stratifiedkfold = StratifiedKFold(n_splits=10) #K=10分割
scores = cross_val_score(clf, X_train, y_train, cv=stratifiedkfold)
print('Cross-Validation scores: {}'.format(scores)) # 各分割におけるスコア
print('Average score: {}'.format(np.mean(scores))) # スコアの平均値
kmeans = MiniBatchKMeans(n_clusters=7, max_iter=300)
kmeans_result = kmeans.fit_predict(X_train)
features = X_train.columns
with open("tree.dot", 'w') as f:
tree.export_graphviz(
clf,
out_file=f,
feature_names=features,
filled=True,
rounded=True,
special_characters=True,
impurity=False,
proportion=False,
class_names=list(map(str, range(0, np.max(kmeans_result)+1)))
)Score: 0.27173435546622315 Cross-Validation scores: [0.16014322 0.1993833 0.22275287 0.23680694 0.23153493 0.19696691 0.21440115 0.25998513 0.24984117 0.22169596] Average score: 0.21935115860744903
実際の正答率:81.4%
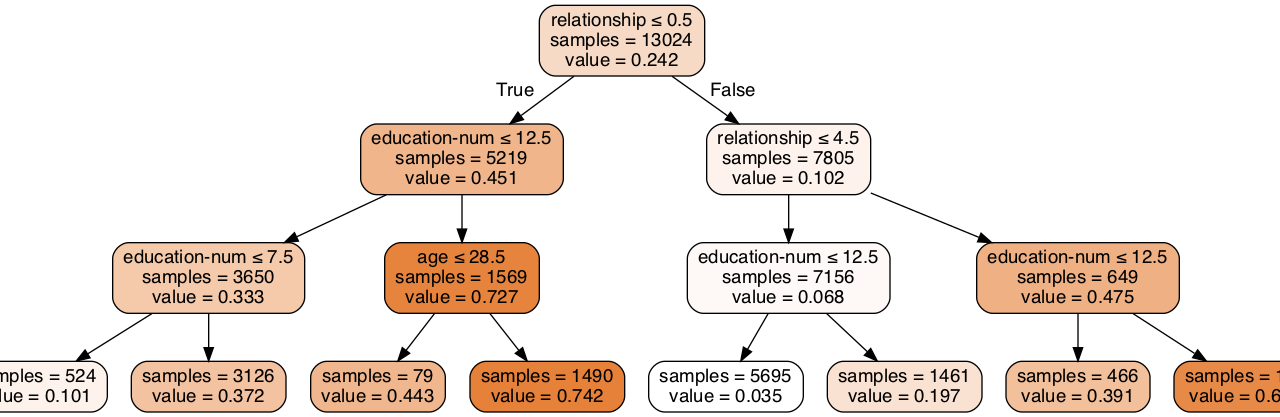
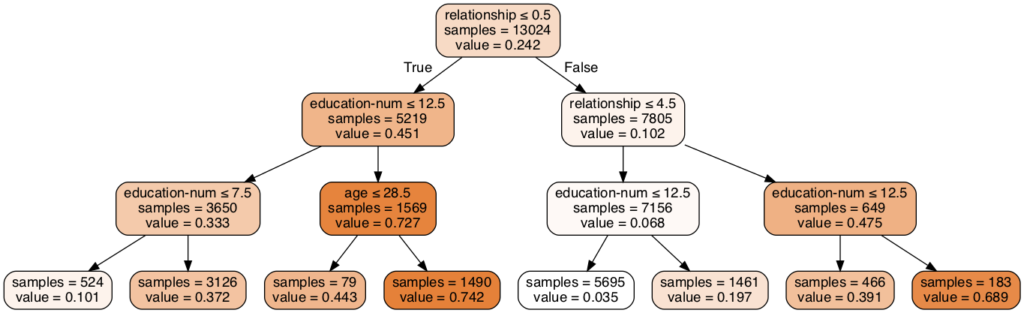
決定木の中身を見る
print(y_pred)
for i in range(16281):
if y_pred[i]>=0.5:
y_pred[i]=1
else:
y_pred[i]=0
print(y_pred)
# sub['id'] = test['id']
sub['Y'] = list(map(int, y_pred))
sub['Y']=sub['Y'].replace([1, 0], [">50K", "<=50K"])
sub.to_csv('submission.csv', index=False)import pydotplus
from IPython.display import Image
graph = pydotplus.graphviz.graph_from_dot_file('tree.dot')
graph.write_png('tree.png')
Image(graph.create_png())max_depth=20の場合

max_depth=3の場合
ランダムフォレスト
clf = RandomForestClassifier(n_estimators=100, max_depth=20, random_state=1)
clf.fit(X_train, y_train)
y_pred = clf.predict(test)
print ('Score: ',clf.score(X_test, y_test))#正解率の表示
#K分割交差検証
stratifiedkfold = StratifiedKFold(n_splits=10) #K=10分割
scores = cross_val_score(clf, X_train, y_train, cv=stratifiedkfold)
print('Cross-Validation scores: {}'.format(scores)) # 各分割におけるスコア
print('Average score: {}'.format(np.mean(scores))) # スコアの平均値Score: 0.8108108108108109 Cross-Validation scores: [0.78741366 0.79969302 0.79892556 0.80583269 0.8172043 0.80798771 0.80875576 0.81490015 0.8156682 0.79185868] Average score: 0.804823973507904
実際の正答率:80.9%
ロジスティック回帰
clf = LogisticRegression(penalty='l2', solver='sag', random_state=1)
clf.fit(X_train, y_train)
y_pred = clf.predict(test)
print ('Score: ',clf.score(X_test, y_test))#正解率の表示
#K分割交差検証
stratifiedkfold = StratifiedKFold(n_splits=10) #K=10分割
scores = cross_val_score(clf, X_train, y_train, cv=stratifiedkfold)
print('Cross-Validation scores: {}'.format(scores)) # 各分割におけるスコア
print('Average score: {}'.format(np.mean(scores))) # スコアの平均値Score: 0.7926904176904177
Cross-Validation scores: [0.78434382 0.7981581 0.80122794 0.81427475 0.80721966 0.78725038 0.79800307 0.79262673 0.79953917 0.78417819] Average score: 0.7966821809059326
実際の正答率:80.2%