
Python-docxはPythonの環境でWordを操作できるライブラリの一つです。
特にテキストの抽出やテーブル内のセル内容の抽出が容易にできるので覚えておいて損はないライブラリです。
今回は公式サイトを元にWord内のデータを抽出すること、抽出したデータを別のWordファイルへ保存すること、様々な仕様で新規にwordファイルを作る一連の流れまで紹介していきます。
最終成果イメージ
最終的にはこのようなファイルが作れるようになります。

ゼロからwordファイルを作成する
インストール方法
Python環境の導入がまだの方はこちらの記事を先に読んでください。

AnacondaのJupyter notebookを開き、以下の一行を実行することでインストール完了です。
pip install python-docxインポート方法
docxをインポートします。
import docxWordファイルを新規に作成する
document = Document()タイトルを作成する
.add_headingで段落を追加することができます。
第二引数はレベルを指し、0の場合はタイトルとして設定されます。
document.add_heading('PythonでWordを操作', 0)テキストの入力と書式指定
.add_paragraphでテキストを入力できます。
.add_run(●●).bold、.add_run(●●)italicで●●の部分を太字や斜体にすることができます。
p = document.add_paragraph('Python-docxはPythonの環境で')
p.add_run('Word').bold = True
p.add_run(' を操作できる')
p.add_run('ライブラリの一つです').italic = Truestyle=”でスタイルを変更できます。
Intense Quoteは引用で使われるスタイルです。
document.add_heading('インストール方法', level=1)
document.add_paragraph('pip install python-docx', style='Intense Quote')style=を’List Bullet’とすると「・」、’List Number’とすると「1,2,3・・・」と表示されていきます。
document.add_paragraph(
'抽出できるデータ', style='List Bullet'
)
document.add_paragraph(
'テキスト、テーブルのデータ、図', style='List Number'
)図の挿入
.add_picture()で図の挿入ができます。
width=Inches()で幅のインチサイズを調整できます。
document.add_picture('docx-1.png', width=Inches(2.25))テーブル(表)の作成
作成するテーブルの中身をrecordsとして用意します。
records = (
(1, '3/11', '●●●'),
(2, '3/12', '◆◆◆'),
(3, '3/13', '▲▲▲')
)add_table()でテーブルが作成できます。
hdr_cells=table.rows[0].cellsで行の最初のセルを指定、hdr_cells[0].textで1行1列目を’ID’と指定します。
2列目、3列目と同様に指定していくと列の項目名が入力されます。
for文以降で先ほどのrecordsの中身を代入していきます。
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'ID'
hdr_cells[1].text = '日付'
hdr_cells[2].text = '内容'
for qty, id, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = descWordファイルを保存する
add_page_break()で1ページをここで終了することができます。
document.add_page_break()doc.save(‘●●.docx’)で●●というファイル名でワードを保存できます。
doc.save("test.docx")【全文】Wordファイルを作成するコード
from docx import Document
from docx.shared import Inches
document = Document()
document.add_heading('PythonでWordを操作', 0)
p = document.add_paragraph('Python-docxはPythonの環境で')
p.add_run('Word').bold = True
p.add_run(' を操作できる')
p.add_run('ライブラリの一つです').italic = True
document.add_heading('インストール方法', level=1)
document.add_paragraph('pip install python-docx', style='Intense Quote')
document.add_paragraph(
'抽出できるデータ', style='List Bullet'
)
document.add_paragraph(
'テキスト、テーブルのデータ、図', style='List Number'
)
document.add_picture('docx-1.png', width=Inches(2.25))
records = (
(1, '3/11', '●●●'),
(2, '3/12', '◆◆◆'),
(3, '3/13', '▲▲▲')
)
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'ID'
hdr_cells[1].text = '日付'
hdr_cells[2].text = '内容'
for qty, id, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc
document.add_page_break()
document.save('test.docx')既にあるワードファイルからデータを抽出する方法
Wordファイルを読み込む
doc = docx.Document("test.docx")Wordの構成を確認する
※ここでは本記事の最後に作成するwordファイルを読み込む例です。
print("段落の個数:", len(doc.paragraphs))
print("表の個数:", len(doc.tables))
print("図(行内)の個数:", len(doc.inline_shapes))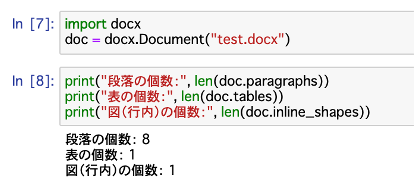
各構成の情報がこのように確認できます。
今後、データ抽出する際に念頭に置く情報として重要になるのでこの確認方法は要チェックです。
段落のテキストデータを抽出
段落のテキストデータを読み込む場合はparagraphs[]で段落数を指定します。
0とすると一番初めの段落のテキストとなります。
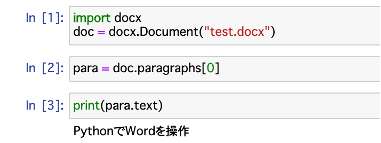
para = doc.paragraphs[0].textでテキストが抽出できます。
実際にprint文で表示させてみます。
print(para.text)「PythonでWordを操作」と出力されました。
表のセル値を抽出
表の場合はtable[]でテーブル番号を指定します。
今回はテーブルが一つしかないので、0と指定します。
tbl = doc.tables[0].cell(●,●).textで抽出できます。
抽出したテキストを表示させてみます。
print(tbl.cell(1,1).text)
print(tbl.cell(1,2).text)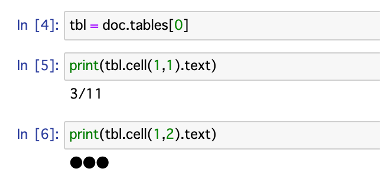
以上で解説は終わりです。















