
目次
グラフ整列について
整列手法の候補
本記事ではplotlyで複数のグラフを整列することを中心とした例文をいくつか紹介していきます。
①plotly_expressのfacet機能を使う方法
▶︎初心者向け
②make_subplots機能を使う方法
▶︎初心者向け
③make_subplots機能+for文を使う方法
▶︎中級者向け
①plotly_expressのfacet機能を使う方法
まずはplotly_expressをインポートします。
import plotly.express as px
plotly_expressのインストールがまだの方はpipでインストールできます。
pip install plotly_expressデータはplotly内で用意されているgapminderを使用し、大陸はオセアニアに絞ります。
facet_row=’country’とすることでオセアニアの中にある国別に行方向に分割されたグラフが得られます。
facet_rowではx軸の値が共通になります。
facet_colではy軸の値が共通になります。
コードとサンプルグラフ
df = px.data.gapminder().query("continent=='Oceania'")
fig = px.line(df, x="year", y="lifeExp", facet_row='country')
fig.show()
facetの有効活用に関する記事
facetの使い方についてはこちらの記事で詳しく紹介しています。

【plotlyレイアウト応用編】<<第1回>>Facet and Trellis Plots活用
はじめに
本記事の内容について
plotlyレイアウト応用編ではグラフの見せ方について実例を紹介しながら学べる講座になりま...
②make_subplots機能を使う方法
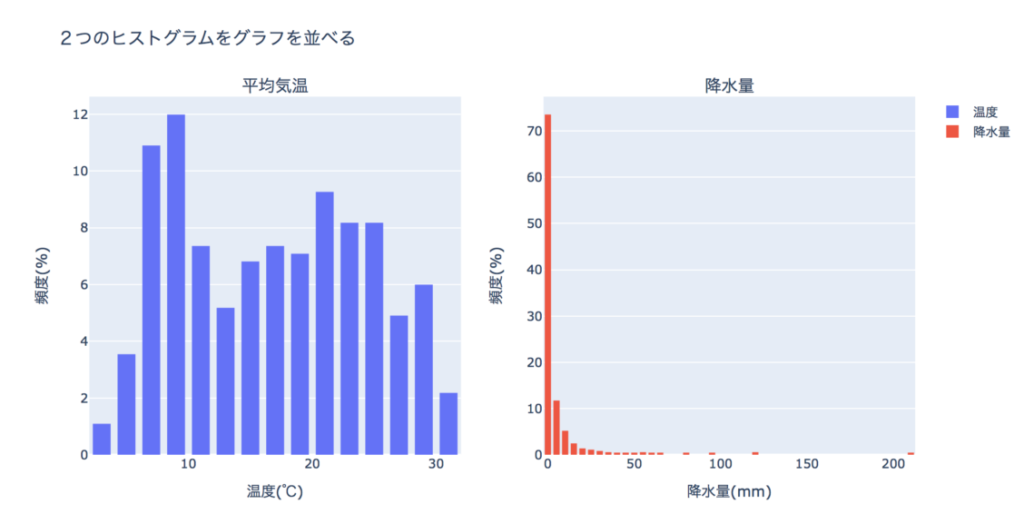
2つのヒストグラムを左右に並べてみます。
使用する元データについて(気象庁のデータ取得)
気象庁から気温のデータを使用した例です。
↓取得する手順を知りたい方はこちらから
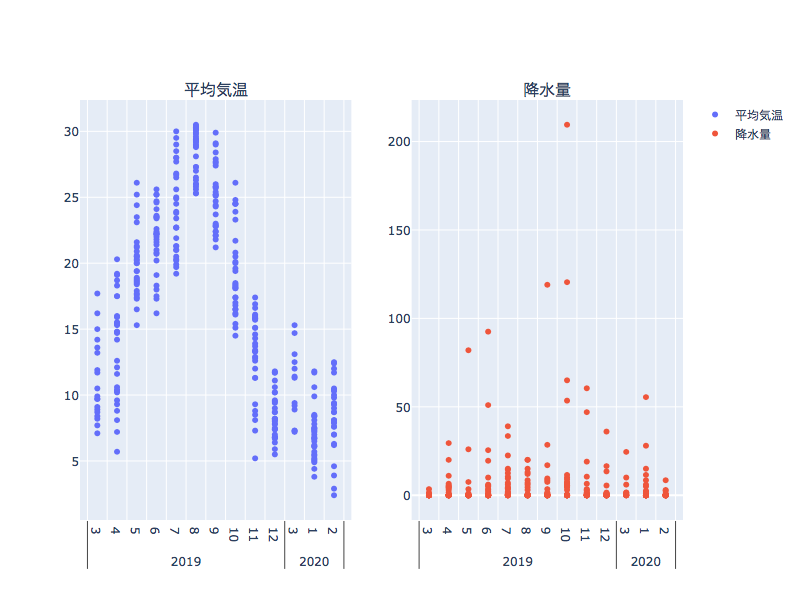
【CSVデータのグラフ化にはPlotlyとPythonが便利】気象データの散布図を作成する例
本記事ではCSVデータからグラフ化するフリーソフトの一つであるPlotlyについてCSVのデータを微調整してグラフ化する簡単な例を紹介...
2つのグラフを並べる(棒グラフ×2)
import plotly.graph_objects as go
import pandas as pd
import numpy as np
from plotly.subplots import make_subplots
df = pd.read_csv('tokyo.csv')
fig = make_subplots(
rows=1, cols=2,
subplot_titles=("平均気温", "降水量"))
fig.add_trace(
go.Histogram(x=df["temperature"],histnorm='percent',name='温度'),
row=1, col=1
)
fig.add_trace(
go.Histogram(x=df["precipitation"],histnorm='percent',name='降水量'),
row=1, col=2
)
fig.update_layout(
title_text='2つのヒストグラムをグラフを並べる',
xaxis_title_text='温度(℃)',
yaxis_title_text='頻度(%)',
bargap=0.2, #隣接する位置座標のバー間のギャップ
bargroupgap=0.1 # 同じ位置座標のバー間のギャップ
)
fig.update_layout(
xaxis2_title_text='降水量(mm)',
yaxis2_title_text='頻度(%)',
bargap=0.2, #隣接する位置座標のバー間のギャップ
bargroupgap=0.1 # 同じ位置座標のバー間のギャップ
)
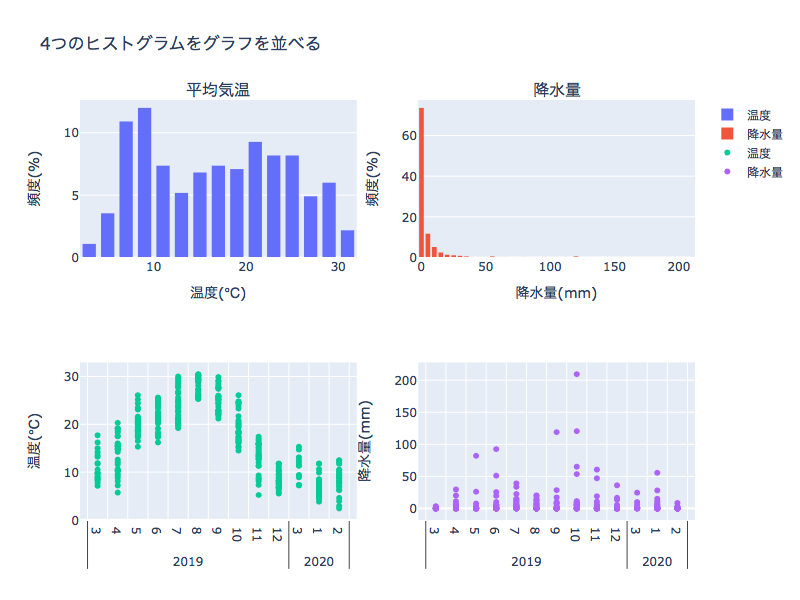
4つのグラフを並べる(棒グラフ×2、散布図×2)
import plotly.graph_objects as go
import pandas as pd
import numpy as np
from plotly.subplots import make_subplots
df = pd.read_csv('tokyo.csv')
fig = make_subplots(
rows=2, cols=2,
subplot_titles=("平均気温", "降水量"))
fig.add_trace(
go.Histogram(x=df["temperature"],histnorm='percent',name='温度'),
row=1, col=1
)
fig.add_trace(
go.Histogram(x=df["precipitation"],histnorm='percent',name='降水量'),
row=1, col=2
)
fig.add_trace(
go.Scatter(x=(df['year'],df['month']), y=df['temperature'], mode='markers',name='温度'),
row=2,col=1
)
fig.add_trace(
go.Scatter(x=(df['year'],df['month']), y=df['precipitation'], mode='markers',name='降水量'),
row=2,col=2
)
fig.update_layout(
title_text='4つのヒストグラムをグラフを並べる',
xaxis_title_text='温度(℃)',
yaxis_title_text='頻度(%)',
bargap=0.2,
bargroupgap=0.1
)
fig.update_layout(
xaxis2_title_text='降水量(mm)',
yaxis2_title_text='頻度(%)',
bargap=0.2,
bargroupgap=0.1
)
fig.update_layout(
yaxis3_title_text='温度(℃)',
)
fig.update_layout(
yaxis4_title_text='降水量(mm)',
)
③make_subplots機能+for文を使う方法
forを行と列分繰り返し、fig.add_traceに行列をjとiで指定してセットすると②の例のようにコードが長文にならず、シンプルなコードになります。
②で使用していたrow=、col=は省略ができます。
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import numpy as np
N = 20
x = np.linspace(0, 1, N)
fig = make_subplots(3, 3)
for i in range(1, 4):
for j in range(1, 4):
fig.add_trace(go.Scatter(x=x, y=np.random.random(N)), j, i)
fig.update_xaxes(matches='x')
fig.show()














