本記事ではCSVデータからグラフ化するフリーソフトの一つであるPlotlyについてCSVのデータを微調整してグラフ化する簡単な例を紹介します。
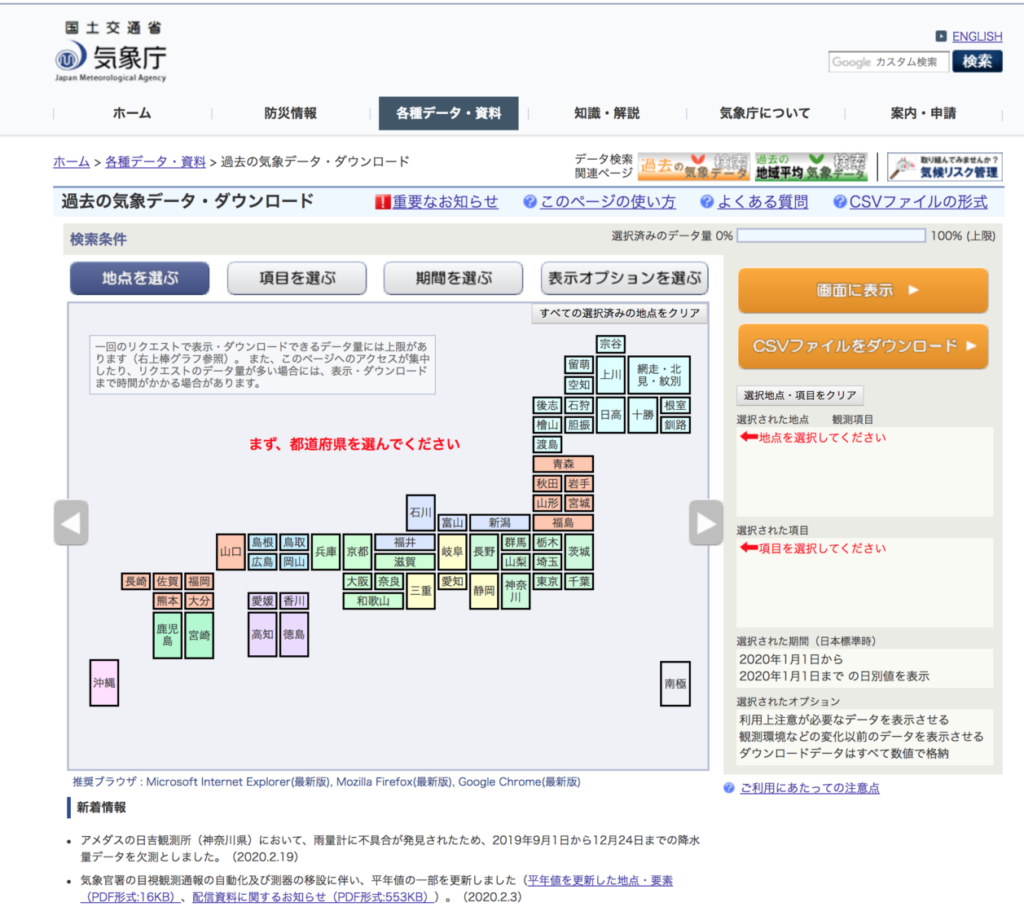
まずはCSVの元データですが、今回は気象庁のWebサイトから気象データをダウンロードしてきます。
今回は東京都の平均気温と降水量を選択してCSVファイルを取得します。
次にJupyter Notebookで取得した「data.csv」をアップロードします。
画面右上の「Upload」ボタンを押してファイルを選択すればOKです。
「New」→「Python3」をクリックして新しいブックを開きます。
#入力データ
in_file = "data.csv"
#トリミング後のデータ
out_file = "tokyo.csv"
# CSVファイルを一行ずつ読み込み
with open(in_file, "rt", encoding="Shift_JIS") as fr: lines = fr.readlines()
# デフォルトのヘッダを削除して、新たなヘッダを作成
lines = ["year,month,day,temperature,1,2,precipitation,3,4,5\n"] + lines[5:]
lines = map(lambda v: v.replace('/', ','), lines)
result = "".join(lines).strip()
# 結果をファイルへ出力
with open(out_file, "wt", encoding="utf-8") as fw:
fw.write(result)
print("saved.")すると、tokyo.csvというデータがJupyter Notebook内に保存されます。
ヘッダを一度削除して新しく作成する理由はPlotlyで日本語が原因のエラーが出ることがあることと、余分なデータ・文字があるとそれもグラフに反映されてしまうからです。
それでは実際に上記プログラムで再作成したデータの中身を見てみましょう。
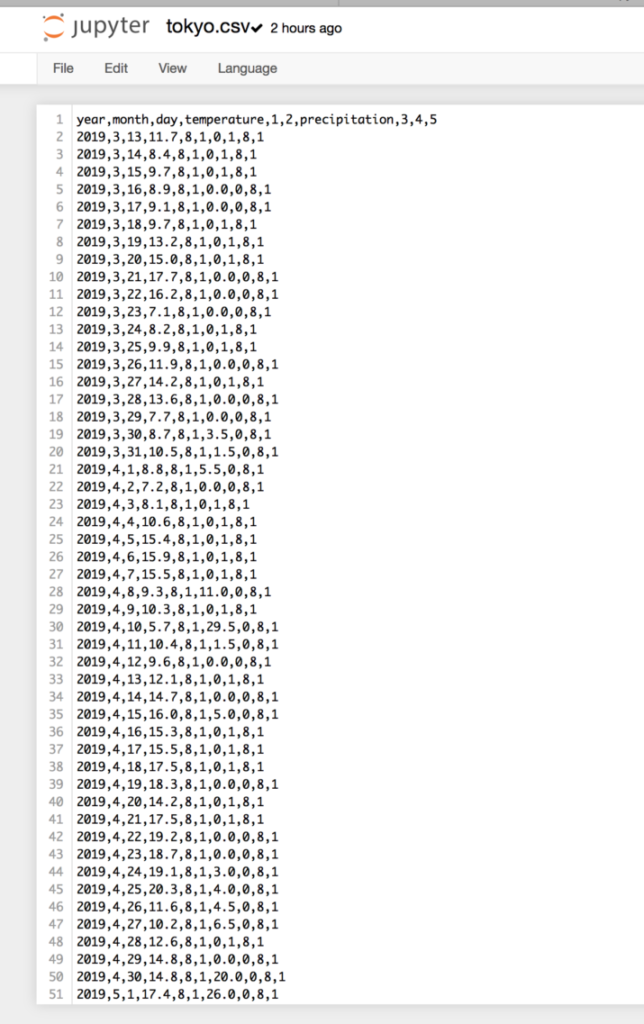
各データがCSVの形式で保存されています。
また、ラベルも記入した通りに書き換えられていることがわかります。
それでは本題のPlotlyを使って、年・月別の平均気温を散布図にプロットしてみます。
Plotly本文に以下コマンドを入力します。
import plotly.graph_objects as go
import pandas as pd
df = pd.read_csv('tokyo.csv')
fig = go.Figure(data=go.Scatter(x=(df['year'],df['month']), y=df['temperature'], mode='markers'))
fig.show()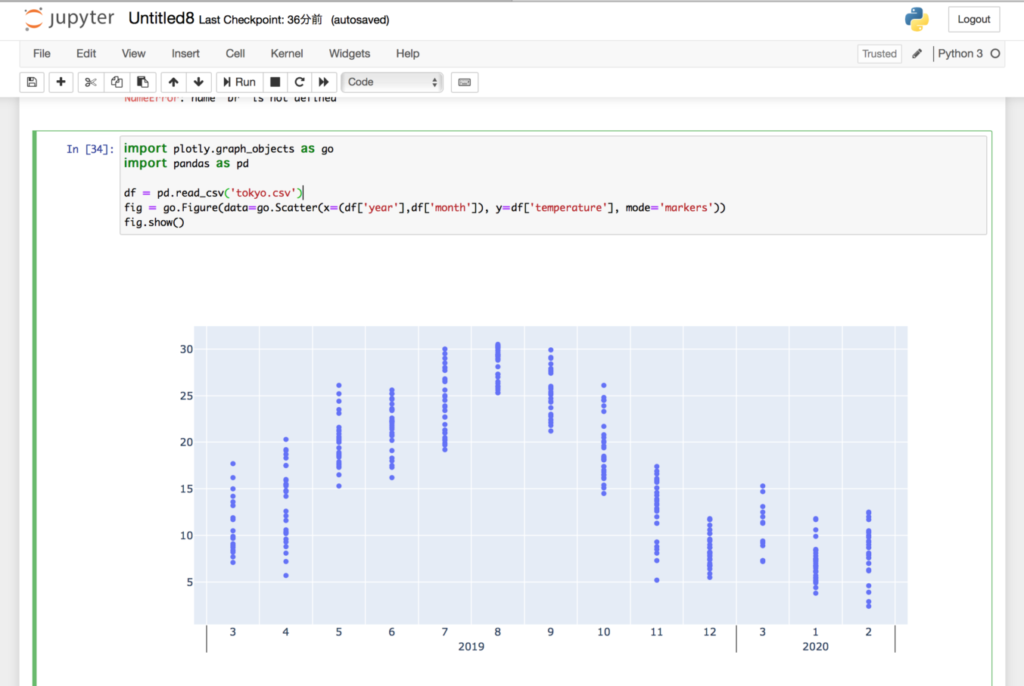
続いて、平均気温と降水量の散布図を2つ並べた例を紹介します。
以下のコードを入力して実行すると
import plotly.graph_objects as go
import pandas as pd
import numpy as np
from plotly.subplots import make_subplots
df = pd.read_csv('tokyo.csv')
fig = make_subplots(
rows=1, cols=2,
subplot_titles=("平均気温", "降水量"))
fig.add_trace(
go.Scatter(x=(df['year'],df['month']), y=df['temperature'], mode='markers'),
row=1,col=1
)
fig.add_trace(
go.Scatter(x=(df['year'],df['month']), y=df['precipitation'], mode='markers'),
row=1,col=2
)
fig.show()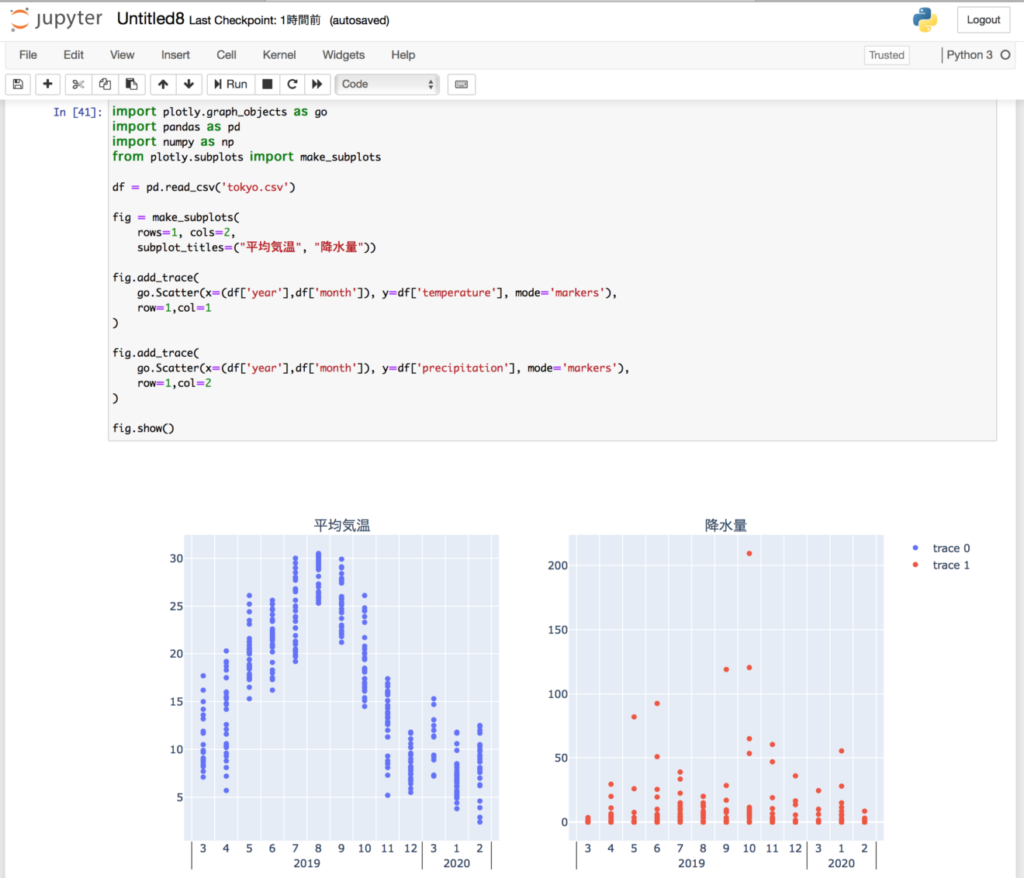
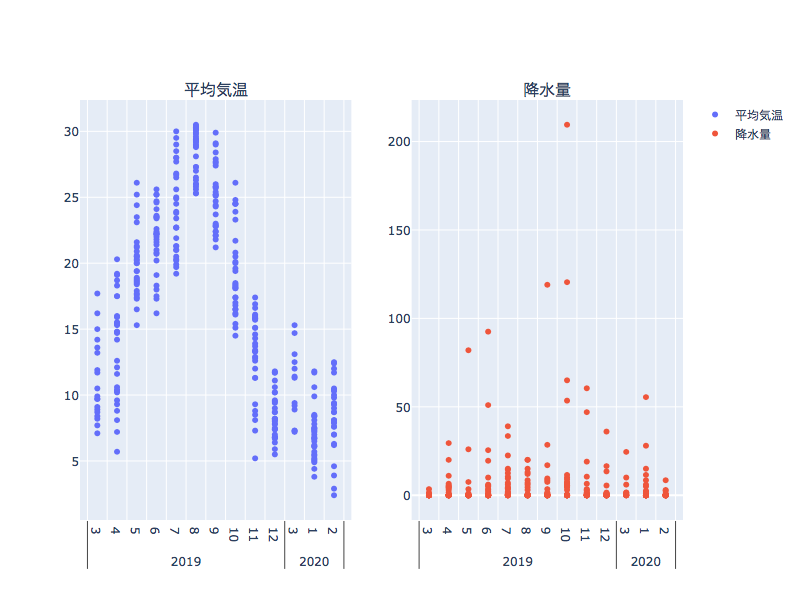
このように平均気温と降水量が年・月ごとにプロットできました。
散布図で同じ月にたくさんプロットがあるのは日ごとのデータを反映させているからです。
プログラムの中身は数行で簡単にグラフ化できることができました。
今回は基本的な散布図の紹介でしたが、他にもPlotlyに関する記事を書いているので見ていってください。
本記事で使用したPythonのコードはこちらの教材を参考にさせていただきました。
















