データの準備
2020年度のコーヒー生豆輸入量のcsvデータを使用します。
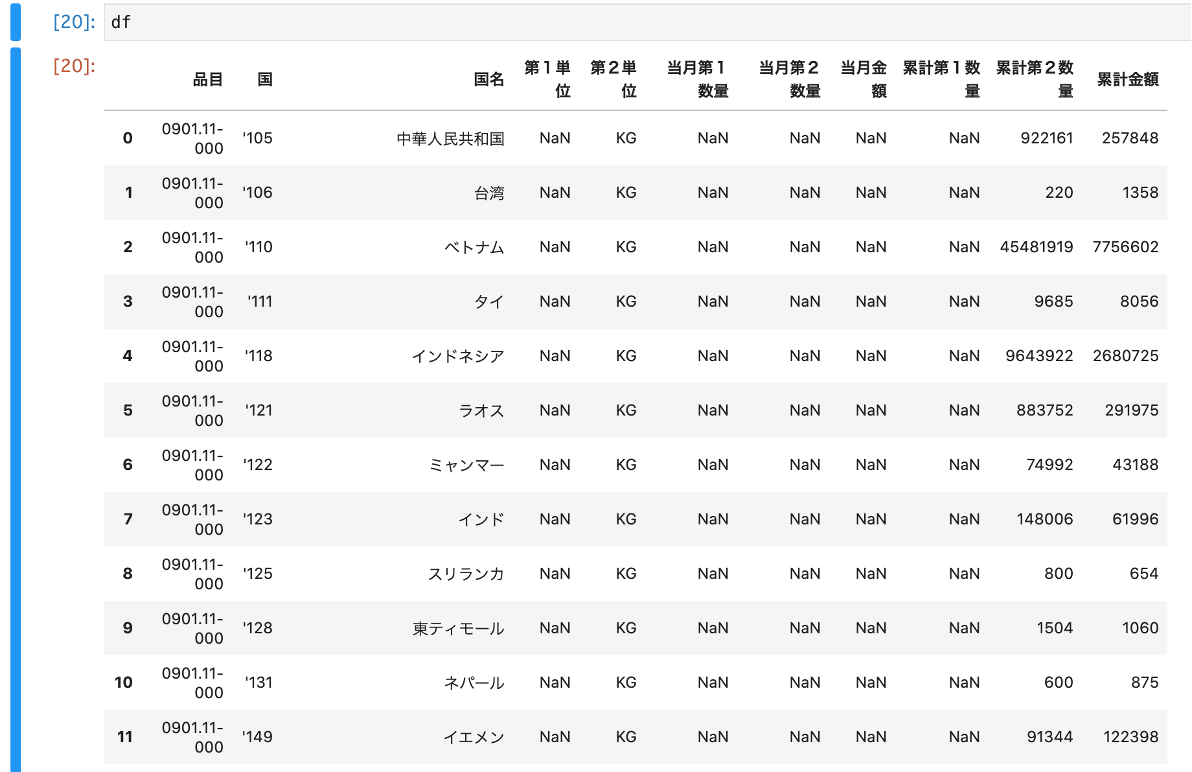
事前に不要なデータを削除しています。
行削除については下記記事を参考にしてください。

【Pandasで簡単データ解析】行指定してCSVファイルを読み込む
データの用意
データは財務省貿易統計からコーヒー生豆の輸入についてデータを取得します。
品目コードは0901110...
データ結合について
本記事では2019年度のデータと2020年度のデータを結合してみます。
まずはpandasをインポートします。
import pandas as pd結合するcsvを読み込みます。
encoding=’shift_jis’で日本語を対応させます。
df_2019 = pd.read_csv('2019.csv',encoding='shift_jis')
df_2020 = pd.read_csv('2020.csv',encoding='shift_jis')元データには年度の情報が抜けてしまうので新しく年度の情報を列に加えます。
df_2019['年度']=2019
df_2020['年度']=2020concatを使った結合
pd.concat([データフレーム1,データフレーム2])で1と2のデータフレームを結合することができます。
その際、列名は共通化されるので簡単にデータ解析に移行できます。
df_concat = pd.concat([df_2019, df_2020])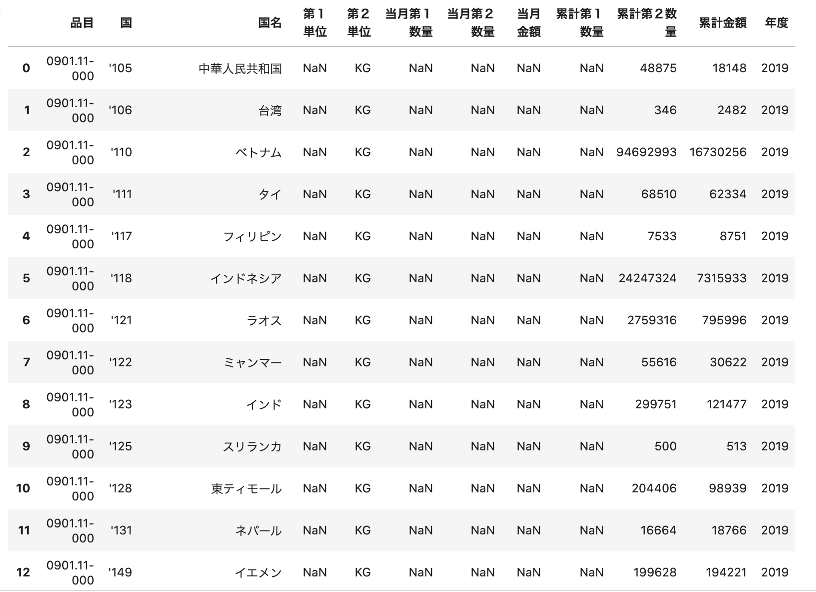
今回は必要ないですが、右に連結したい場合はaxis=1を追加します。
df_concat = pd.concat([df_2019, df_2020], axis=1)データの可視化
import plotly.express as px
import plotly.io as pio
fig = px.bar(df_concat, x="国名", y="累計金額",facet_row="年度")
fig.show()